
VCVerifier provides the necessary endpoints(see API) to offer SIOP-2/OIDC4VP compliant authentication flows. It exchanges VerfiableCredentials for JWT, that can be used for authorization and authentication in down-stream components.



![]()
![]()
VerifiableCredentials provide a mechanism to represent information in a tamper-evident and therefor trustworthy way. The term “verifiable” refers to the characteristic of a credential being able to be verified by a 3rd party(e.g. a verifier). Verification in that regard means, that it can be proven, that the claims made in the credential are as they were provided by the issuer of that credential.
This characteristics make VerifiableCredentials a good option to be used for authentication and authorization, as a replacement of other credentials types, like the traditional username/password. The SIOP-2/OIDC4VP standards define a flow to request and present such credentials as an extension to the well-established OpenID Connect.
The VCVerifier provides the necessary endpoints required for a Relying Party(as used in the SIOP-2 spec) to participate in the authentication flows. It verifies the credentials using the Trustbloc Libraries to provide Verfiable Credentials specific functionality and return a signed JWT, containing the credential as a claim, to be used for further interaction by the participant.
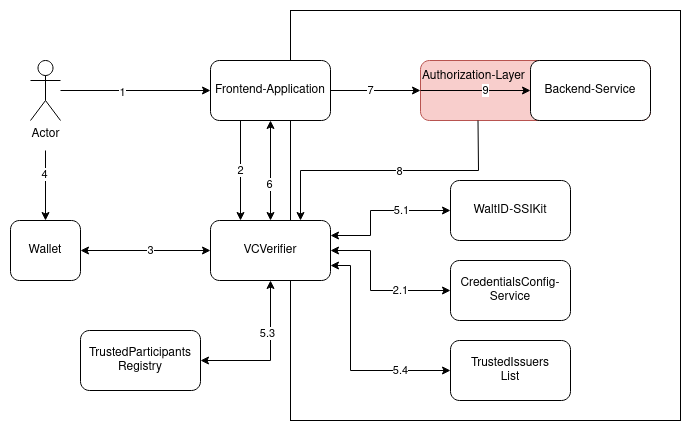
The following diagram shows an example of how the VCVerifier would be placed inside a system, using VerifiableCredentials for authentication and authorization. It pictures a Human-2-Machine flow, where a certain user interacts with a frontend and uses its dedicated Wallet(for example installed on a mobile phone) to participate in the SIOP-2/OIDC4VP flow.

The following actions occur in the interaction:
- The user opens the frontend application.
- The frontend-application forwards the user to the login-page of VCVerifier
- The VCVerifier presents a QR-code, containing the
openid:-connection string with all necessary information to start the authentication process. The QR-code is scanned by the user’s wallet.- the Verifier retrieves the Scope-Information from the Config-Service
- The user approves the wallet’s interaction with the VCVerifier and the VerifiableCredential is presented via the OIDC4VP-flow.
- VCVerifier verifies the credential:
- at WaltID-SSIKit with the configured set of policies
- (Optional) if a Gaia-X compliant chain is provided
- that the credential is registered in the configured trusted-participants-registries
- that the issuer is allowed to issuer the credential with the given claims by one of the configured trusted-issuers-list(s)
- A JWT is created, the frontend-application is informed via callback and the token is retrieved via the token-endpoint.
- Frontend start to interact with the backend-service, using the jwt.
- Authorization-Layer requests the JWKS from the VCVerifier(this can happen asynchronously, not in the sequential flow of the diagram).
- Authorization-Layer verifies the JWT(using the retrieved JWKS) and handles authorization based on its contents.
The VCVerifier is provided as a container and can be run via docker run -p 8080:8080 quay.io/fiware/vcverifier.
To ease the deployment on Kubernetes environments, the helm-chart i4trust/vcverfier can be used.
Since the VCVerifier requires a Trusted Issuers Registry and someone to issuer credentials, a local setup is not directly integrated into this repository. However, the VC-Integration-Test repository provides an extensive setup of various components participating in the flows. It can be used to run a local setup, either for trying-out or as a basis for further development. Run it via:
git clone git@github.com:fiware/VC-Integration-Test.git
cd VC-Integration-Test/
mvn clean integration-test -PdevSee the documentation in that repo for more information.
The configuration has to be provided via config-file. The file is either loaded from the default location at ./server.yaml or from a location configured via the environment-variable CONFIG_FILE. See the following yaml for documentation and default values:
# all configurations related to serving the endpoints
server:
# port to bin to
port: 8080
# folder to load the template pages from
templateDir: "views/"
# directory to load static content from
staticDir: "views/static/"
# logging configuration
logging:
# the log level, accepted options are DEBUG, INFO, WARN and ERROR
level: "INFO"
# should the log output be in structured json-format
jsonLogging: true
# should the verifier log all incoming requests
logRequests: true
# a list of paths that should be excluded from the request logging. Can f.e. be used to omit continuous health-checks
pathsToSkip:
# configuration directly connected to the functionality
verifier:
# did to be used by the verifier.
did:
# identification of the verifier in communication with wallets
clientIdentification:
# identification used by the verifier when requesting authorization. Can be a did, but also methods like x509_san_dns
id:
# path to the signing key(in pem format) for request object. Needs to correspond with the id
keyPath:
# algorithm to be used for signing the request. Needs to match the signing key
requestKeyAlgorithm:
# depending on the id type, the certificate chain needs to be included in the object(f.e. in case of x509_san_dns)
certificatePath:
# supported modes for requesting authentication. in case of byReference and byValue, the clientIdentification needs to be properly configured
supportedModes: ["urlEncoded", "byReference","byValue"]
# address of the (ebsi-compliant) trusted-issuers-registry to be used for verifying the issuer of a received credential
tirAddress:
# Expiry(in seconds) of an authentication session. After that, a new flow needs to be initiated.
sessionExpiry: 30
# scope(e.g. type of credential) to be requested from the wallet. if not configured, not specific scope will be requested.
requestScope:
# Validation mode for validating the vcs. Does not touch verification, just content validation.
# applicable modes:
# * `none`: No validation, just swallow everything
# * `combined`: ld and schema validation
# * `jsonLd`: uses JSON-LD parser for validation
# * `baseContext`: validates that only the fields and values (when applicable)are present in the document. No extra fields are allowed (outside of credentialSubject).
# Default is set to `none` to ensure backwards compatibility
validationMode:
# algorithm to be used for the jwt signatures - currently supported: RS256 and ES256, default is RS256
keyAlgorithm:
# when set to true, the private key is generated on startup. Its not persisted and just kept in memory.
generateKey: true
# path to the private key(in PEM format) for jwt signatures
keyPath:
# configuration of the service to retrieve configuration for
configRepo:
# endpoint of the configuration service, to retrieve the scope to be requested and the trust endpoints for the credentials.
configEndpoint: http://config-service:8080
# static configuration for services
services:
# name of the service to be configured
- id: testService
# default scope for the service
defaultOidcScope: "default"
# the concrete scopes for the service, defining the trust for credentials and the presentation definition to be requested
oidcScopes:
# the concrete scope configuration
default:
# credentials and their trust configuration
credentials:
- type: CustomerCredential
# trusted participants endpoint configuration
trustedParticipantsLists:
# the credentials type to configure the endpoint(s) for
VerifiableCredential:
- https://tir-pdc.ebsi.fiware.dev
# the credentials type to configure the endpoint(s) for
CustomerCredential:
- https://tir-pdc.ebsi.fiware.dev
# trusted issuers endpoint configuration
trustedIssuersLists:
# the credentials type to configure the endpoint(s) for
VerifiableCredential:
- https://tir-pdc.ebsi.fiware.dev
# the credentials type to configure the endpoint(s) for
CustomerCredential:
- https://tir-pdc.ebsi.fiware.dev
# configuration for verifying the holder of a credential
holderVerification:
# should it be checked?
enabled: true
# claim to retrieve the holder from
claim: subject
# credentials and claims to be requested
presentationDefinition:
id: my-presentation
# List of requested inputs
input_descriptors:
id: my-descriptor
# defines the infromation to be requested
constraints:
# array of objects to describe the information to be included
fields:
- id: my-field
path:
- $.vct
filter:
const: "CustomerCredential"
# format of the credential to be requested
format:
'sd+jwt-vc':
alg: ES256The login-page, provided at /api/v1/loginQR, can be configured by providing a different template in the templateDir. The templateDir needs to contain a file named verifier_present_qr.html which will be rendered on calls to the login-api. The template needs to include the QR-Code via <img src="data:{{.qrcode}}". Beside that, all options provided by the goview-framework can be used. Static content(like icons, images) can be provided through the staticDir and will be available at the path /static.
The VCVerifier provides support for integration in frontend-applications(e.g. typical H2M-interactin) or plain api-usage(mostly M2M).
In order to ease the integration into frontends, VCVerifier offers a login-page at /api/v1/loginQR. The loginQr-endpoint expects a state(that will be used on the callback, so that the calling frontend-application can identify the user-session) and a client_callback url, which will be contacted by the verifier after successfull verfication via GET with the query-parameters state(the originally send state) and code(which is the authorization_code to be provided at the token endpoint for retrieving the actual JWT).
In order to start a same-device-flow(e.g. the credential is hold by the requestor, instead of an additional device like a mobile wallet) call:
curl -X 'GET' \
'http://localhost:8080/api/v1/samedevice?state=274e7465-cc9d-4cad-b75f-190db927e56a'The response will be a 302-Redirect, containing a locationheader with all necessary parameters to continue the process. If the redirect should go to an alternative path, provide the redirect_pathquery parameter.
location: http://localhost:8080/?response_type=vp_token&response_mode=direct_post&client_id=did:key:z6MkigCEnopwujz8Ten2dzq91nvMjqbKQYcifuZhqBsEkH7g&redirect_uri=http://verifier-one.batterypass.fiware.dev/api/v1/authentication_response&state=OUBlw8wlCZZOcTwRN2wURA&nonce=wqtpm60Jwx1sYWITRRZwBw
The redirect should be taken and then answered via authentication_response-endpoint. Make sure that the vp_token and presentation_submission use Base64-URL-Safe encoding, instead of just Base64-encoding.
curl -X 'POST' \
'https://localhost:8080/api/v1/authentication_response?state=OUBlw8wlCZZOcTwRN2wURA' \
-H 'accept: */*' \
-H 'Content-Type: application/x-www-form-urlencoded' \
-d 'presentation_submission=ewogICJpZCI6ICJzdHJpbmciLAogICJkZWZpbml0aW9uX2lkIjogIjMyZjU0MTYzLTcxNjYtNDhmMS05M2Q4LWZmMjE3YmRiMDY1MyIsCiAgImRlc2NyaXB0b3JfbWFwIjogWwogICAgewogICAgICAiaWQiOiAiaWRfY3JlZGVudGlhbCIsCiAgICAgICJmb3JtYXQiOiAibGRwX3ZjIiwKICAgICAgInBhdGgiOiAiJCIsCiAgICAgICJwYXRoX25lc3RlZCI6ICJzdHJpbmciCiAgICB9CiAgXQp9&vp_token=ewogICJAY29udGV4dCI6IFsKICAgICJodHRwczovL3d3dy53My5vcmcvMjAxOC9jcmVkZW50aWFscy92MSIKICBdLAogICJ0eXBlIjogWwogICAgIlZlcmlmaWFibGVQcmVzZW50YXRpb24iCiAgXSwKICAidmVyaWZpYWJsZUNyZWRlbnRpYWwiOiBbCiAgICB7CiAgICAgICJ0eXBlcyI6IFsKICAgICAgICAiUGFja2V0RGVsaXZlcnlTZXJ2aWNlIiwKICAgICAgICAiVmVyaWZpYWJsZUNyZWRlbnRpYWwiCiAgICAgIF0sCiAgICAgICJAY29udGV4dCI6IFsKICAgICAgICAiaHR0cHM6Ly93d3cudzMub3JnLzIwMTgvY3JlZGVudGlhbHMvdjEiLAogICAgICAgICJodHRwczovL3czaWQub3JnL3NlY3VyaXR5L3N1aXRlcy9qd3MtMjAyMC92MSIKICAgICAgXSwKICAgICAgImNyZWRlbnRpYWxzU3ViamVjdCI6IHt9LAogICAgICAiYWRkaXRpb25hbFByb3AxIjoge30KICAgIH0KICBdLAogICJpZCI6ICJlYmM2ZjFjMiIsCiAgImhvbGRlciI6IHsKICAgICJpZCI6ICJkaWQ6a2V5Ono2TWtzOW05aWZMd3kzSldxSDRjNTdFYkJRVlMyU3BSQ2pmYTc5d0hiNXZXTTZ2aCIKICB9LAogICJwcm9vZiI6IHsKICAgICJ0eXBlIjogIkpzb25XZWJTaWduYXR1cmUyMDIwIiwKICAgICJjcmVhdG9yIjogImRpZDprZXk6ejZNa3M5bTlpZkx3eTNKV3FINGM1N0ViQlFWUzJTcFJDamZhNzl3SGI1dldNNnZoIiwKICAgICJjcmVhdGVkIjogIjIwMjMtMDEtMDZUMDc6NTE6MzZaIiwKICAgICJ2ZXJpZmljYXRpb25NZXRob2QiOiAiZGlkOmtleTp6Nk1rczltOWlmTHd5M0pXcUg0YzU3RWJCUVZTMlNwUkNqZmE3OXdIYjV2V002dmgjejZNa3M5bTlpZkx3eTNKV3FINGM1N0ViQlFWUzJTcFJDamZhNzl3SGI1dldNNnZoIiwKICAgICJqd3MiOiAiZXlKaU5qUWlPbVpoYkhObExDSmpjbWwwSWpwYkltSTJOQ0pkTENKaGJHY2lPaUpGWkVSVFFTSjkuLjZ4U3FvWmphME53akYwYWY5WmtucXgzQ2JoOUdFTnVuQmY5Qzh1TDJ1bEdmd3VzM1VGTV9abmhQald0SFBsLTcyRTlwM0JUNWYycHRab1lrdE1LcERBIgogIH0KfQ'The post will be answered with just another redirect, containing the state and the code to be used for retrieving the JWT:
location: http://localhost:8080/?state=274e7465-cc9d-4cad-b75f-190db927e56a&code=IwMTgvY3JlZGVudGlhbHMv
The original requestor now can use to retrieve the JWT through the standarad token flow:
curl -X 'POST' \
'https://localhost:8080/token' \
-H 'accept: application/json' \
-H 'Content-Type: application/x-www-form-urlencoded' \
-d 'grant_type=authorization_code&code=IwMTgvY3JlZGVudGlhbHMv&redirect_uri=https%3A%2F%2Flocalhost%3A8080%2F'which will be answered with(demo jwt, will be signed in reality):
{
"token_type": "Bearer",
"expires_in": 3600,
"access_token": "ewogICJhbGciOiAiRVMyNTYiLAogICJraWQiOiAiV09IRnU0SFo1OVNNODUzQzdlTjBPdmxLR3JNZWVyRENwSE9VUm9UUXdIdyIsCiAgInR5cCI6ICJKV1QiCn0.ewogICJAY29udGV4dCI6IFsKICAgICJodHRwczovL3d3dy53My5vcmcvMjAxOC9jcmVkZW50aWFscy92MSIKICBdLAogICJ0eXBlIjogWwogICAgIlZlcmlmaWFibGVQcmVzZW50YXRpb24iCiAgXSwKICAidmVyaWZpYWJsZUNyZWRlbnRpYWwiOiBbCiAgICB7CiAgICAgICJ0eXBlcyI6IFsKICAgICAgICAiUGFja2V0RGVsaXZlcnlTZXJ2aWNlIiwKICAgICAgICAiVmVyaWZpYWJsZUNyZWRlbnRpYWwiCiAgICAgIF0sCiAgICAgICJAY29udGV4dCI6IFsKICAgICAgICAiaHR0cHM6Ly93d3cudzMub3JnLzIwMTgvY3JlZGVudGlhbHMvdjEiLAogICAgICAgICJodHRwczovL3czaWQub3JnL3NlY3VyaXR5L3N1aXRlcy9qd3MtMjAyMC92MSIKICAgICAgXSwKICAgICAgImNyZWRlbnRpYWxzU3ViamVjdCI6IHt9LAogICAgICAiYWRkaXRpb25hbFByb3AxIjoge30KICAgIH0KICBdLAogICJpZCI6ICJlYmM2ZjFjMiIsCiAgImhvbGRlciI6IHsKICAgICJpZCI6ICJkaWQ6a2V5Ono2TWtzOW05aWZMd3kzSldxSDRjNTdFYkJRVlMyU3BSQ2pmYTc5d0hiNXZXTTZ2aCIKICB9LAogICJwcm9vZiI6IHsKICAgICJ0eXBlIjogIkpzb25XZWJTaWduYXR1cmUyMDIwIiwKICAgICJjcmVhdG9yIjogImRpZDprZXk6ejZNa3M5bTlpZkx3eTNKV3FINGM1N0ViQlFWUzJTcFJDamZhNzl3SGI1dldNNnZoIiwKICAgICJjcmVhdGVkIjogIjIwMjMtMDEtMDZUMDc6NTE6MzZaIiwKICAgICJ2ZXJpZmljYXRpb25NZXRob2QiOiAiZGlkOmtleTp6Nk1rczltOWlmTHd5M0pXcUg0YzU3RWJCUVZTMlNwUkNqZmE3OXdIYjV2V002dmgjejZNa3M5bTlpZkx3eTNKV3FINGM1N0ViQlFWUzJTcFJDamZhNzl3SGI1dldNNnZoIiwKICAgICJqd3MiOiAiZXlKaU5qUWlPbVpoYkhObExDSmpjbWwwSWpwYkltSTJOQ0pkTENKaGJHY2lPaUpGWkVSVFFTSjkuLjZ4U3FvWmphME53akYwYWY5WmtucXgzQ2JoOUdFTnVuQmY5Qzh1TDJ1bEdmd3VzM1VGTV9abmhQald0SFBsLTcyRTlwM0JUNWYycHRab1lrdE1LcERBIgogIH0KfQ"
}The Verifier currently supports 2 types of Participant Lists:
💡 The following example configurations are provided through the static yaml file. Its recommended to use the Credentials-Config-Service instead, to have the ability for dynamic changes. All described configurations are supported by the service in version >=2.0.0
In order to check an issuer against an EBSI Trusted Issuers Registry, it needs to be configured for the supported credentials. When using the file config, it would look like:
configRepo:
# static configuration for services
services:
# name of the service to be configured
testService:
# scope to be requested from the wallet
scope:
- VerifiableCredential
# trusted participants endpoint configuration
trustedParticipants:
# the credentials type to configure the endpoint(s) for
VerifiableCredential:
- type: ebsi
# scope to be requested from the wallet
scope:
- VerifiableCredential
- CustomerCredential
url: https://tir-pdc.ebsi.fiware.devFor backward compatibility, the EBSI List is the default at the moment, thus the following (simplified) configuration is also valid:
configRepo:
# static configuration for services
services:
# name of the service to be configured
testService:
# scope to be requested from the wallet
scope:
- VerifiableCredential
# trusted participants endpoint configuration
trustedParticipants:
# the credentials type to configure the endpoint(s) for
VerifiableCredential:
- https://tir-pdc.ebsi.fiware.devWhen using the Gaia-X Digital Clearing House’s Registry Services, the issuer to be checked needs to fullfill the requirements of a Gaia-X participant. Thus, only did:web is supported for such and they need to provide a valid x5u location as part of their publicKeyJwk. Usage of such registries can than be configured as following:
configRepo:
# static configuration for services
services:
# name of the service to be configured
testService:
# scope to be requested from the wallet
scope:
- VerifiableCredential
# trusted participants endpoint configuration
trustedParticipants:
# the credentials type to configure the endpoint(s) for
VerifiableCredential:
- type: gaia-x
url: https://registry.lab.gaia-x.euIts also possible to trust multiple list with different types. In this case, the issuer is trusted if its found in at least one of the lists. Configuration would be as following:
configRepo:
# static configuration for services
services:
# name of the service to be configured
testService:
# scope to be requested from the wallet
scope:
- VerifiableCredential
# trusted participants endpoint configuration
trustedParticipants:
# the credentials type to configure the endpoint(s) for
VerifiableCredential:
- type: ebsi
url: https://tir-pdc.ebsi.fiware.dev
- type: gaia-x
url: https://registry.lab.gaia-x.euIn order to support various wallets, the verifier supports 3 modes of requesting authentication:
- Passing as URL with encoded parameters: “urlEncoded”
- Passing a request object as value: “byValue”
- Passing a request object by reference: “byReference”
Following the RFC9101, in the second and third case the request is encoded as a signed JWT. Therefor clientIdentification for the verifier needs to be properly configured.
The mode can be set during the intial requests, by sending the parameter “requestMode”(see API Spec).Since requestObjects can become large and therefor also the QR-Codes generated out of them, the 3rd mode is recommended.
Example:
openid4vp://?response_type=vp_token&response_mode=direct_post&client_id=did:key:verifier&redirect_uri=https://verifier.org/api/v1/authentication_response&state=randomState&nonce=randomNonce
Example:
openid4vp://?client_id=did:key:verifier&request=eyJhbGciOiJFUzI1NiIsInR5cCI6Im9hdXRoLWF1dGh6LXJlcStqd3QifQ.eyJjbGllbnRfaWQiOiJkaWQ6a2V5OnZlcmlmaWVyIiwiZXhwIjozMCwiaXNzIjoiZGlkOmtleTp2ZXJpZmllciIsIm5vbmNlIjoicmFuZG9tTm9uY2UiLCJwcmVzZW50YXRpb25fZGVmaW5pdGlvbiI6eyJpZCI6IiIsImlucHV0X2Rlc2NyaXB0b3JzIjpudWxsLCJmb3JtYXQiOm51bGx9LCJyZWRpcmVjdF91cmkiOiJodHRwczovL3ZlcmlmaWVyLm9yZy9hcGkvdjEvYXV0aGVudGljYXRpb25fcmVzcG9uc2UiLCJyZXNwb25zZV90eXBlIjoidnBfdG9rZW4iLCJzY29wZSI6Im9wZW5pZCIsInN0YXRlIjoicmFuZG9tU3RhdGUifQ.Z0xv_E9vvhRN2nBeKQ49LgH8lkjkX-weR7R5eCmX9ebGr1aE8_6usa2PO9nJ4LRv8oWMg0q9fsQ2x5DTYbvLdA
Decoded:
{
"alg": "ES256",
"typ": "oauth-authz-req+jwt"
}.
{
"client_id": "did:key:verifier",
"exp": 30,
"iss": "did:key:verifier",
"nonce": "randomNonce",
"presentation_definition": {
"id": "",
"input_descriptors": null,
"format": null
},
"redirect_uri": "https://verifier.org/api/v1/authbyValentication_response",
"response_type": "vp_token",
"scope": "openid",
"state": "randomState"
}.
signatureExample:
openid4vp://?client_id=did:key:verifier&request_uri=verifier.org/api/v1/request/randomState&request_uri_method=get"
The object than can be retrieved via:
curl https://verifier.org/api/v1/request/randomStateThe response will contain an object like already shown in byValue.
The API implements enpoints defined in OIDC4VP and SIOP-2. The OpenAPI Specification of the implemented endpoints can be found at: api/api.yaml.
The VCVerifier does currently not support all functionalities defined in the connected standards(e.g. OIDC4VP and SIOP-2). Users should be aware of the following points:
- the verifier does not offer any endpoint to proof its own identity
- requests to the authentication-response endpoint do accept “presentation_submissions”, but do not evaluate them
- even thought the vp_token can contain multiple credentials and all of them will be verified, just the first one will be included in the JWT
Functionality of the verifier is tested via parameterized Unit-Tests, following golang-bestpractices. In addition, the verifier is integrated into the VC-Integration-Test, involving all components used in a typical, VerifiableCredentials based, scenario.
VCVerifier is licensed under the Apache License, Version 2.0. See LICENSE for the full license text.
© 2023 FIWARE Foundation e.V.
 https://github.com/FIWARE/VCVerifier
https://github.com/FIWARE/VCVerifier