
![]()



本打卡脚本仅供学习交流使用,请勿过分依赖。开发者对使用或不使用本脚本造成的问题不负任何责任,不对脚本执行效果做出任何担保,原则上不提供任何形式的技术支持。
本仓库基于原版,参考修改版并进行修改,增加对出校申请和跨校区报备的支持。目前正持续更新以尽量使得每一天都可以自动打卡,愿完全放开的日子早日到来。
- 20220407: 本人基于之前的脚本,并进行修改以适应现在的打卡版本
- 20220408: 在SECRET中增加是否执行操作的选项,以适应更多需求
- 20220421: 增加每日上传两码功能
- 20220506: 恭喜解封,源代码可用,但增加每日出校报备
- 20220509: 解决打卡系统post链接被修改,上传两码需要GID的问题
- 20220510: 解决上传两码需要sign的问题
- 20220513: 恭喜自动授权安康码,不再需要自动上传安康码
- 20220706: 增加对于不在校等状态的支持,可能有bug
- 20220829: 风头较严,进出校需要人工审核,建议只进行报备和上传行程码
- 20220830: 增加每日对于申请审核跨校区的支持
- 20220909: 再次恭喜解封,并启用原功能
- 20221007: 完善进出校申请和报备的切换,以及行程码上传方法
- 20221018: 出校报备需要两次核酸报告,需要手动上传
- 20221022: 现在申请也过不了,傻逼封控,暂停申请
- 20221107: 再次恭喜解封,并启用原功能
- 20221128: 根据新要求,只能在20点之后报备下一天,更改报备时间
- 20230226: 恭喜全面解封,感谢大家支持,脚本停止运行,愿它永不启用
写在前面:请在自己fork的仓库中修改,并push到自己的仓库,不要直接修改本仓库,也不要将您的修改pull request到本仓库(对本仓库的改进除外)!如果尚不了解github的基本使用方法,请参阅使用议题和拉取请求进行协作/使用复刻和使用议题和拉取请求进行协作/通过拉取请求提议工作更改。
可根据使用视频: Bilibili进行使用。或者可以按照如下步骤操作:
-
将本代码仓库fork到自己的github,并授权打卡系统从权威机构获取安康码信息。
-
根据自己的实际情况修改
runme.py中的前40行数据。 -
将修改好的代码提交到自己的仓库。
-
点击Actions选项卡,点击
I understand my workflows, go ahead and enable them. -
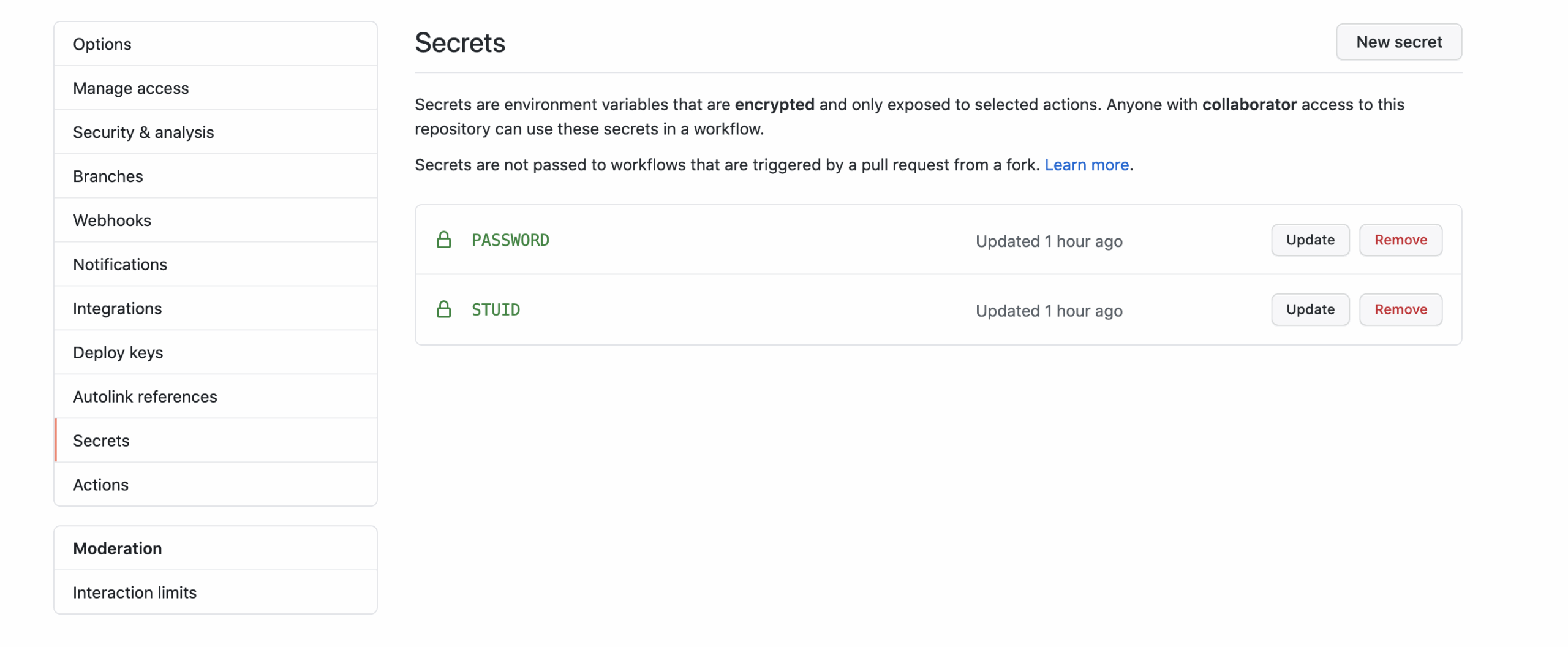
点击Settings选项卡,点击左侧Secrets,点击New secret,创建名为
STUID,值为自己学号的secret。用同样方法,创建名为PASSWORD,值为自己统一身份认证密码的secret。以上数据不会被公开。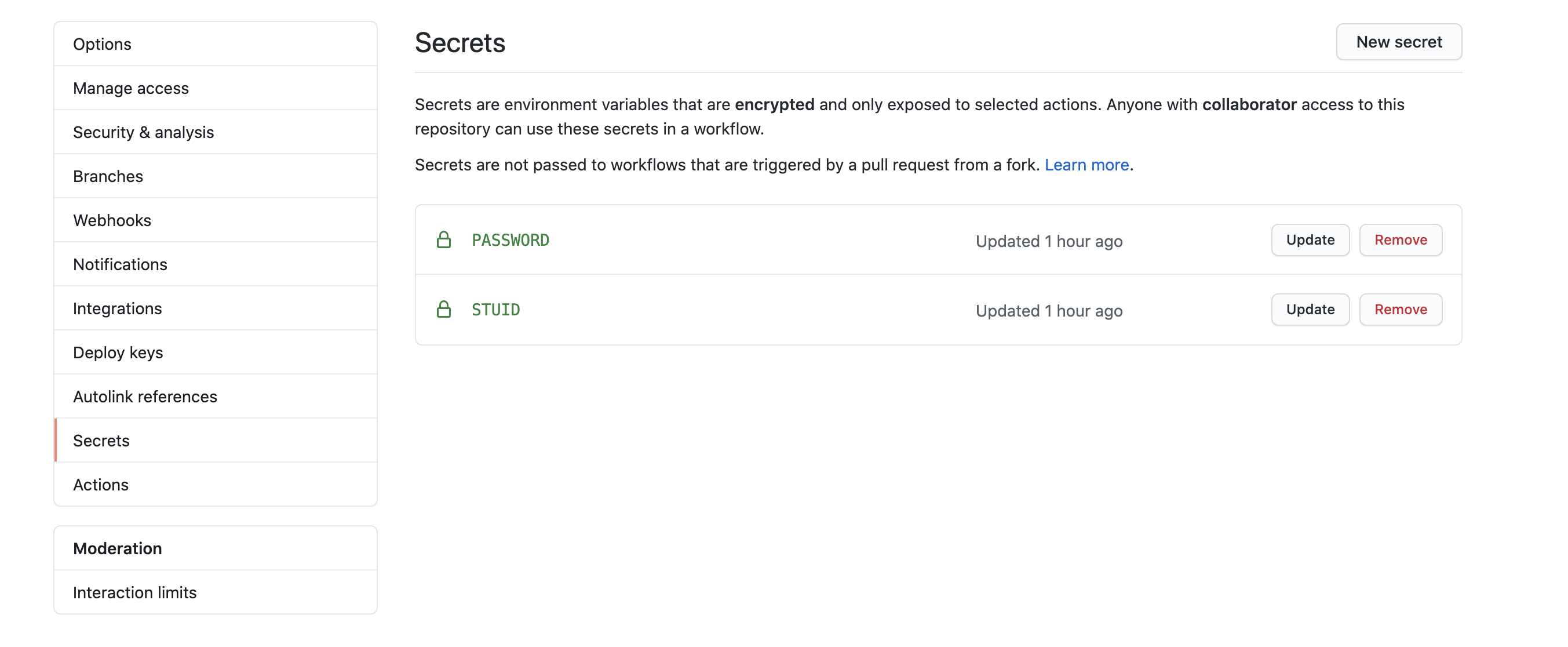
-
默认的打卡时间是每天的上午7:10(建议5点之后,因为5点才会同步安康码),可能会有(延后)几十分钟的浮动。如需选择其它时间,可以修改
.github/workflows/report.yml中的cron,详细说明参见安排的事件,请注意这里使用的是国际标准时间UTC,北京时间的数值比它大8个小时。建议修改默认时间,避开打卡高峰期以提高成功率。 -
在Actions选项卡可以确认打卡情况。如果打卡失败(可能是临时网络问题等原因),脚本会自动重试,五次尝试后如果依然失败,将返回非零值提示构建失败。
-
在Github个人设置页面的Notifications下可以设置Github Actions的通知,建议打开Email通知,并勾选”Send notifications for failed workflows only”。请及时查看邮件,如果失败会进行通知。
-
如果觉得这个仓库对你有用的话,给个星星✨吧~

要在本地运行测试,需要安装python 3。我们假设您已经安装了python 3和pip 3,并已将其路径添加到环境变量。
pip install -r requirements.txtpython runme.py [STUID] [PASSWORD]其中,[STUID]是学号,[PASSWORD]是统一身份认证的密码明文,剩下三个参数为是否出校报备、是否跨校区报备、是否每日打卡,默认不出校,跨校区,打卡。如
python runme.py "PB19890604" "FREEDOM" https://github.com/cyzkrau/AutoDailyReport-For-USTC
https://github.com/cyzkrau/AutoDailyReport-For-USTC